dwayzeR

Using CC unicode symbols in ggplot2
A short tutorial on how to use the icons for the Creative Commons licenses into ggplot2 charts.
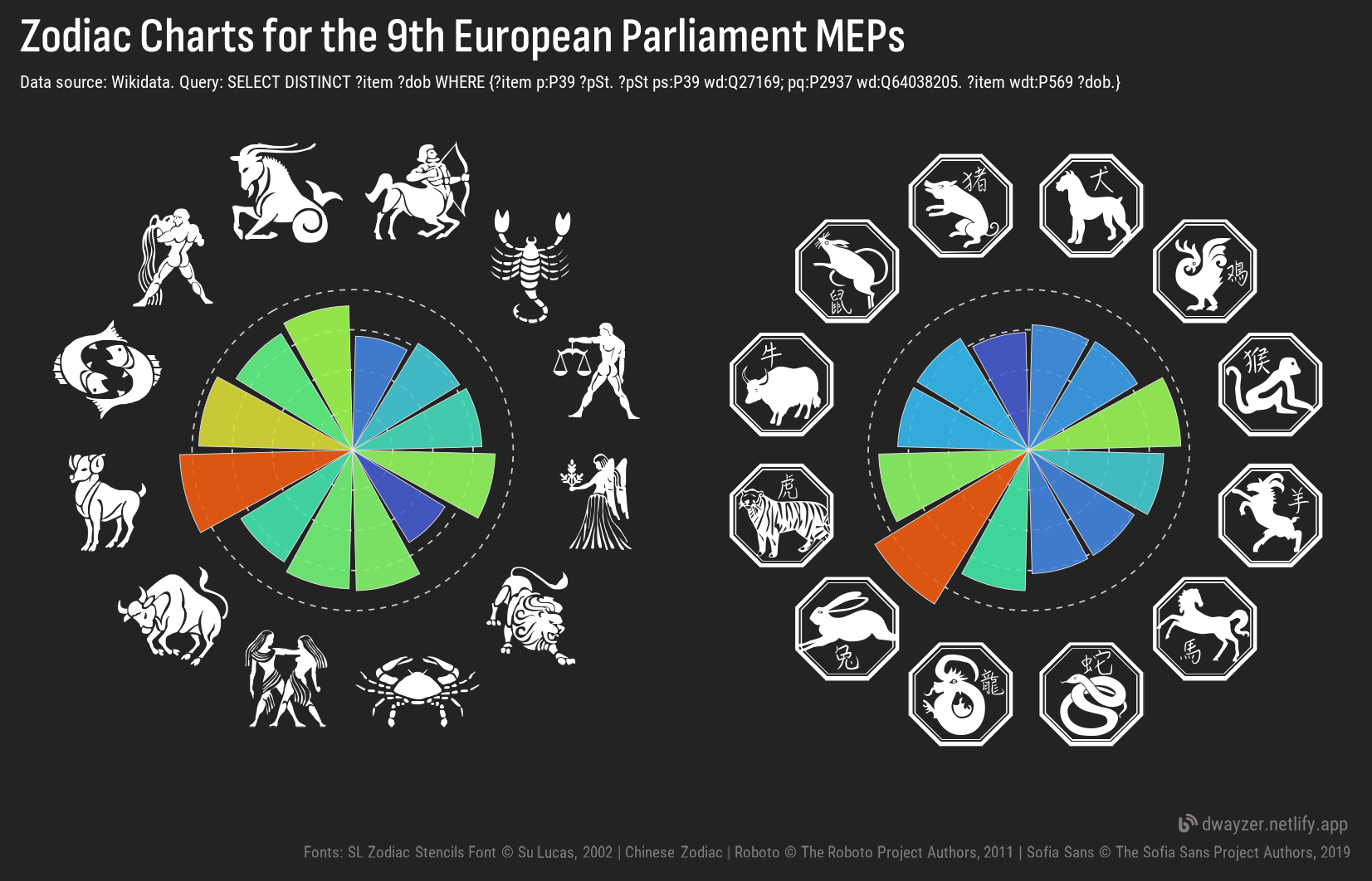
Zodiac Charts
Zodiac signs are popular in many countries. In this post I am offering a routine for creation of fancy zodiac charts based on the birth dates. The example charts are drawn for the elected members of some national parliaments (US House of Representative, UK House of Commons, France National Assembly, German Bundestag, and Russian Duma). The text and the charts are free of any political implications.
Update on RIRO project
RIRO v.1.2 is out! Here are just some personal reflections on RIRO project's development.
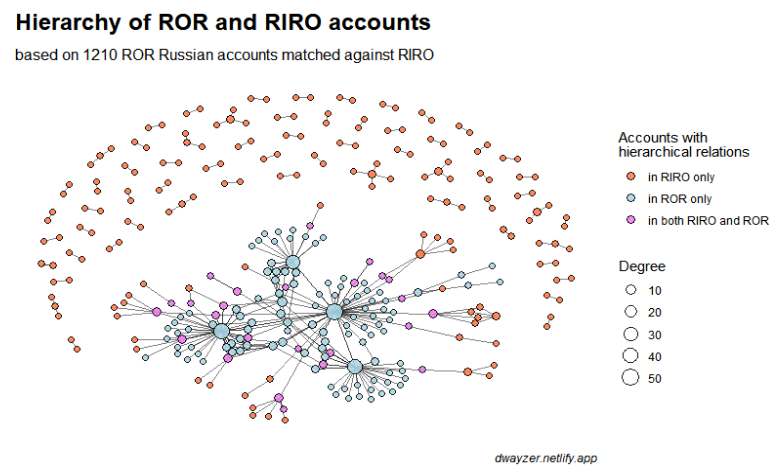
New Release of RIRO is here
RIRO is a Russian Index of Research Organizations and here I am writing about (briefly) what this project is by its 1.1 version.
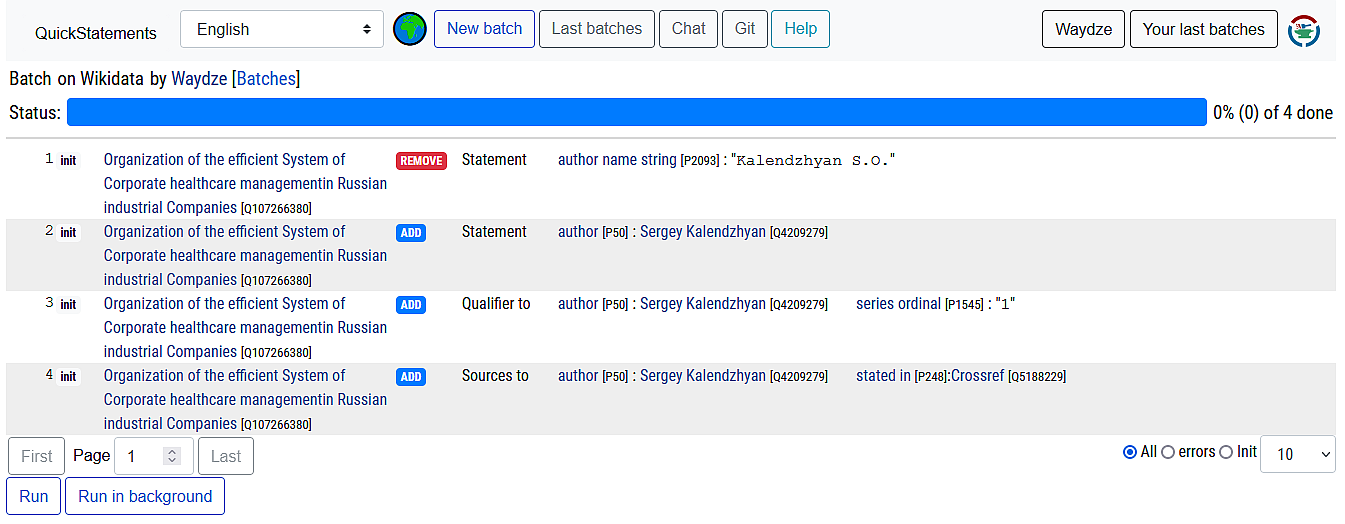
Importing Author Information from CrossRef to Wikidata via QuickStatements
The post continues my quest to improve the presence of academic journal(s) in Wikidata. I reviewed the different searching approaches to find the authors, especially those with with non-English names, in Wikidata and upload the author metadata via QuickStatements.
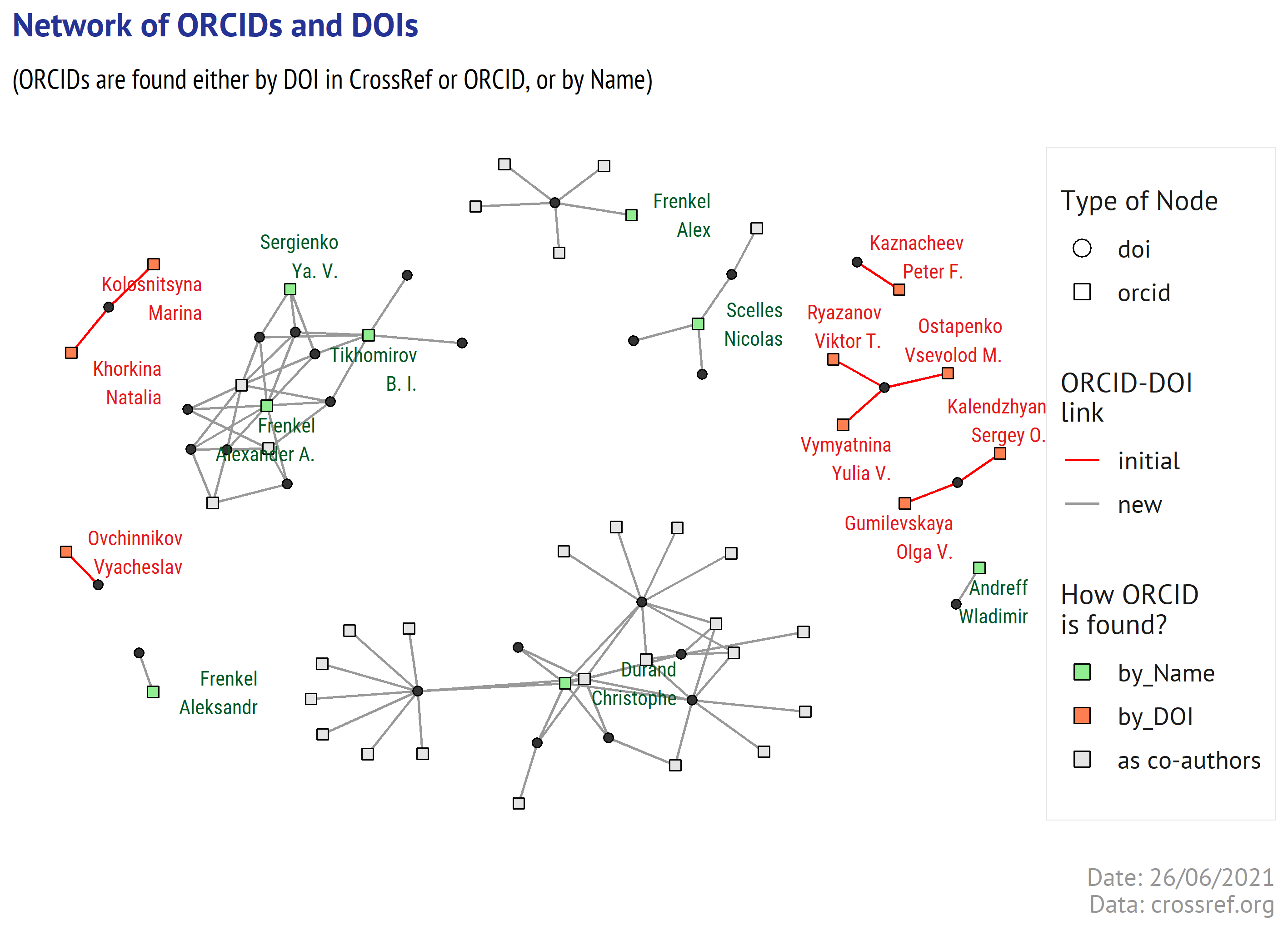
Post-Publication Collecting ORCIDs for the Authors
What if the journal ignored ORCID for years? Is there a simple way to collect their ORCIDs except emailing'em with gentle reminders? In this post I exploit the ways to collect ORCIDs for the authors of already published articles using the open sources (CrossRef, Microsoft Academic, ORCID). Writing it was an unusually long journey, as I had to figth inconsistencies and revise the approaches. An initial share of ORCIDs in CrossRef for the authors of selected articles was 10%. It was raised to 32% with just algorithm-based approach and further was improved to 64% after additional manual check-up of the automatically pre-selected candidates. This is another long post about the scholarly articles, metadata quality, blessed open APIs, and utility of R packages.
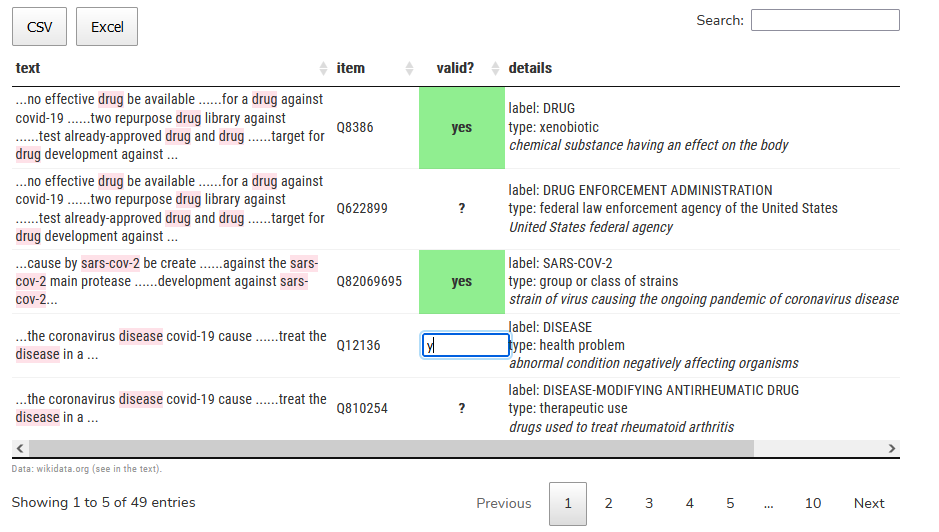
Tagging the Scientific Abstracts with Wikidata Items
Here I am trying to build a script that process the short scientific texts (abstracts) and finds Wikidata items corresponding to the terms. An interactive and editable table is also created to allow an editor to validate the found matches and find other related items. A bit amateurish attempt by a Wikidata newbie.
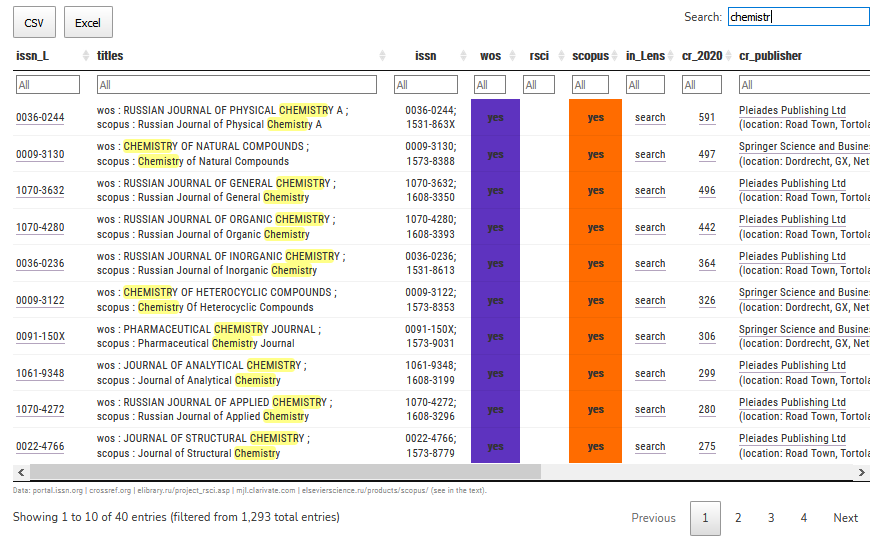
Russian Journals indexed by Scopus, RSCI, and WoS
How difficult it can be to build an aggregated list of the scientific journal titles indexed in A&I databases and citation indices? Extremely difficult, if those venues are the Russian academic journals. In this post I am reviewing the key obstacles and trying to build such a list of the Russian journals indexed in Web of Science Core Collection, Scopus, and RSCI (Russian Citation Index by Web of Science). This is a version updated on June 9, 2021.
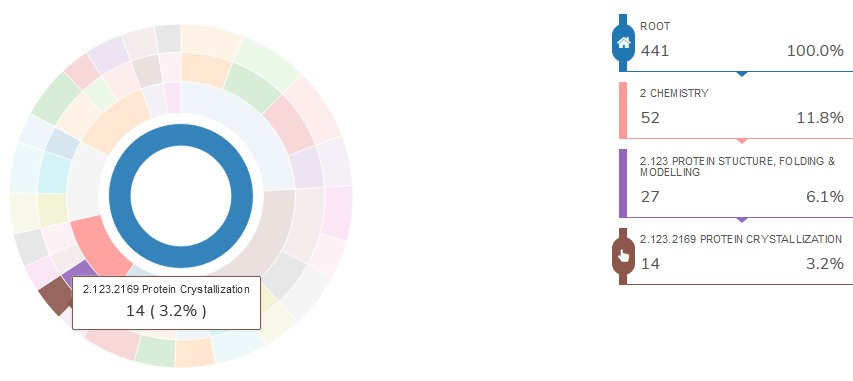
Using R to analyze the InCites (Clarivate) Citation Topics
Even the most succesful information tools can not offer all the possible analytical interfaces or visualization patterns. In this post I am using the R and few htmlwidgets to build a UI for benchmarking the universities based on their InCites citation topics (Clarivate).

National Academic Journals in Wikidata and Wikipedia
In this post I am using SPARQL for searching the Russian academic journals in Wikidata and Wikipedia services, and trying to assess their standing.
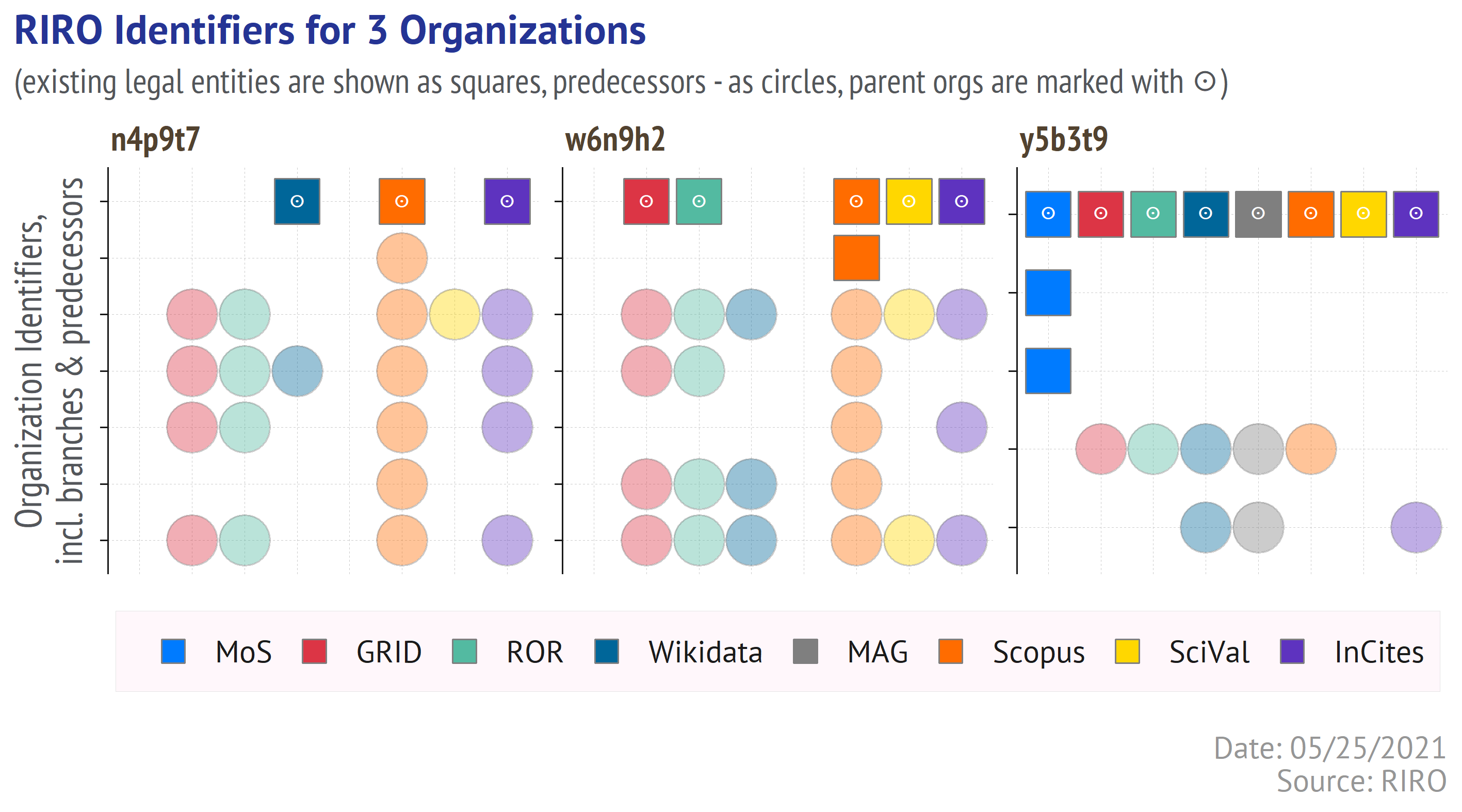
RIRO - Russian Index of the Research Organizations
With Web of Science & Scopus, ROR & GRID, Wikidata & Microsoft Academic, ISNI & other providers of the research organization identifiers, is there a need for another one? In this post I am going to answer this question by telling you about RIRO project, launched by me and Ivan Sterligov today. You will see what RORI is, how to get the data, and what value it can provide for the bibliometric research.
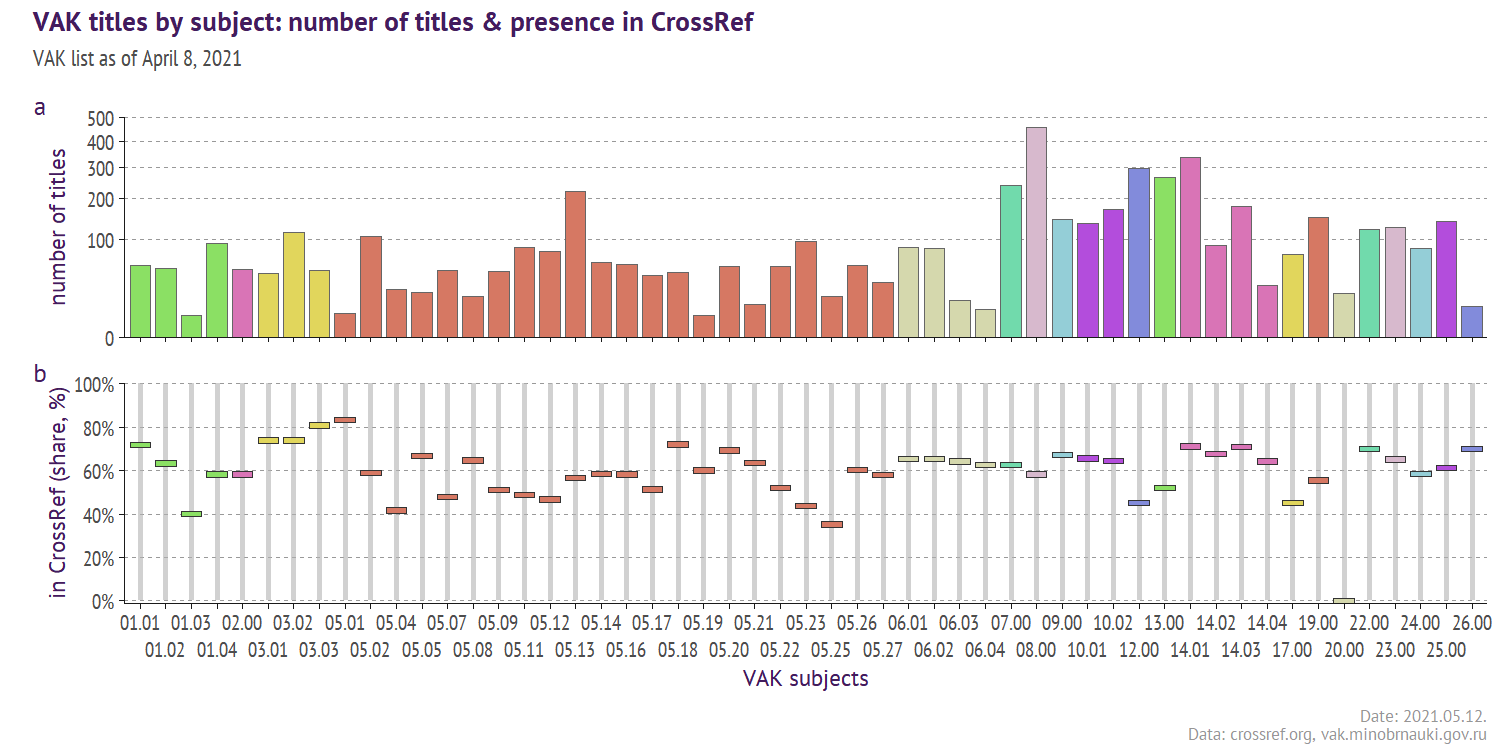
Checking VAK titles in CrossRef
In this post I am checking how many academic journals from the Russian white list (VAK) deposited their 2020/2021 publications in CrossRef. To do that I queried portal.issn.org & CrossRef, and parsed PDF & JSON files, what I think makes this post of interest to those who analyze the academic journals.
Extracting the Tables from PDF
In this post I am using a R package tabulizer to extract a large table from 853-page PDF, containing a list of VAK (Russian) journal titles.